week 3
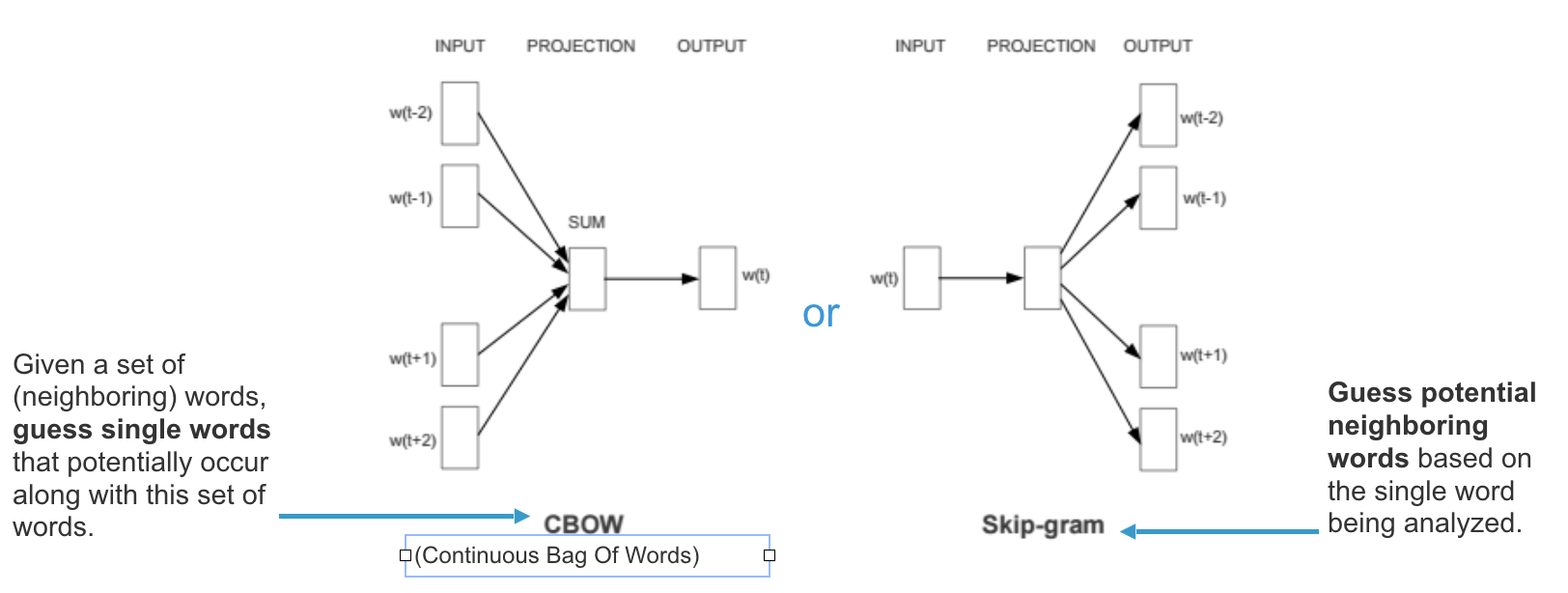
The idea of our project is to find the domain based common words based on the high dimensional represention of the words. In this week I’ve run the continous bag of words CBOW bundle that exist in the ECL to a sample dataset to extract the vector represention of the words in the corpus. I was able to extract the vocabulary from the corpus, extract the high dimensional representation for each word on corpus and find some information about the corpus(vocabulary size, number of occurrence
for each term).