Week 6
In this week we use the LearningTrees (Random Forests) for classification. We used the Random Forests because it’s can handle large numbers of records and large numbers of fields, and, it scales well on HPCC Systems clusters of almost any size.
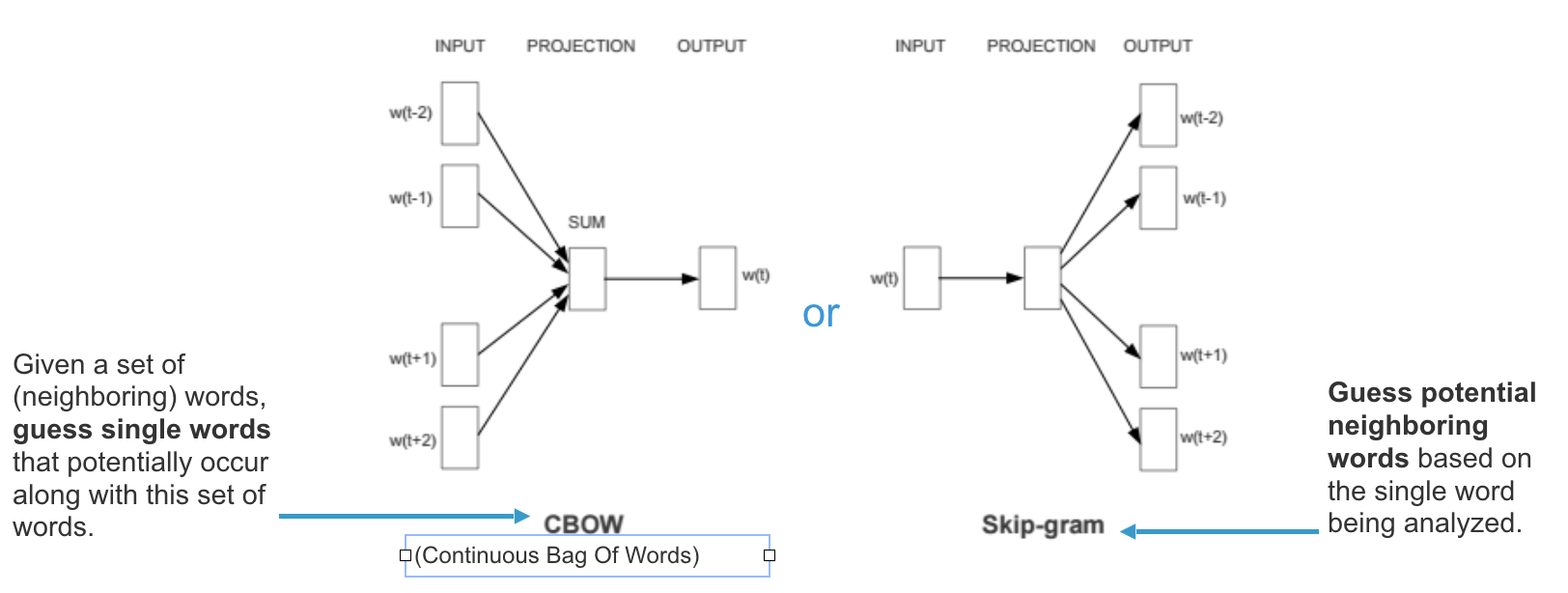
We used the sentence vectors after applying CBOW as input features to Random Forests, and about 20 % of data reserved for testing.
We convert our data (train and test data) to the form used by the ML bundles. Then we separate the Independent Variables and the Dependent Variables. Classification expects Dependent variables to be unsigned integers representing discrete class labels. It therefore expresses Dependent variables using the DiscreteField layout.
We get the assessmentC
record which contains a
Classification_Accuracy record. That record contains the following metrics:
- RecCount – the number of records tested
- ErrCount – the number of mis-classifications
- Raw_Accuracy – the percentage of records that were correctly classified